What is the fundamental process for developing Computer Vision (CV) systems? The answer: Image Annotation.
This blog walks you through the ABCs of image annotation, starting from the fundamentals and progressing to more advanced concepts. Step-by-step you’ll discover how this process, foundational to Chooch, is teaching computers what to see. By the end, you will see how Chooch’s commitment to continuous learning and innovation in AI Vision is reshaping the landscape of computer vision.
A is for Annotation: The basics
Image annotation is the bedrock of computer vision. It is the meticulous process of identifying, labeling, and classifying various components within an image. This could entail drawing bounding boxes around specific objects, highlighting areas of interest, or even tagging individual pixels. The outcome is a comprehensive visual map from which a machine can learn.
In most cases, the annotation task is entrusted to human experts, who bring context, understanding and interpretation to what cameras see. They meticulously label data, creating a rich learning environment for machine learning algorithms. This labeled data is like the textbook for machine learning models, helping them navigate the complex tasks of object detection, image segmentation, and semantic segmentation.
While annotation might sound simple, it is a labor-intensive process that requires a keen eye for detail and a deep understanding of the subject matter. Why is so much effort poured into this task? The answer lies in the quality of the training data.
Think of training data as the fuel for your machine learning engine. The cleaner and more refined the fuel, the smoother and more efficiently the engine runs. Similarly, the accuracy and quality of your image annotations directly influence the effectiveness of your trained image models. In other words, the better the annotations, the better your model will interpret new images. Poorly annotated images might lead to a model that misunderstands or misinterprets visual data, which can have significant implications, particularly in critical applications like medical imaging or autonomous vehicles.
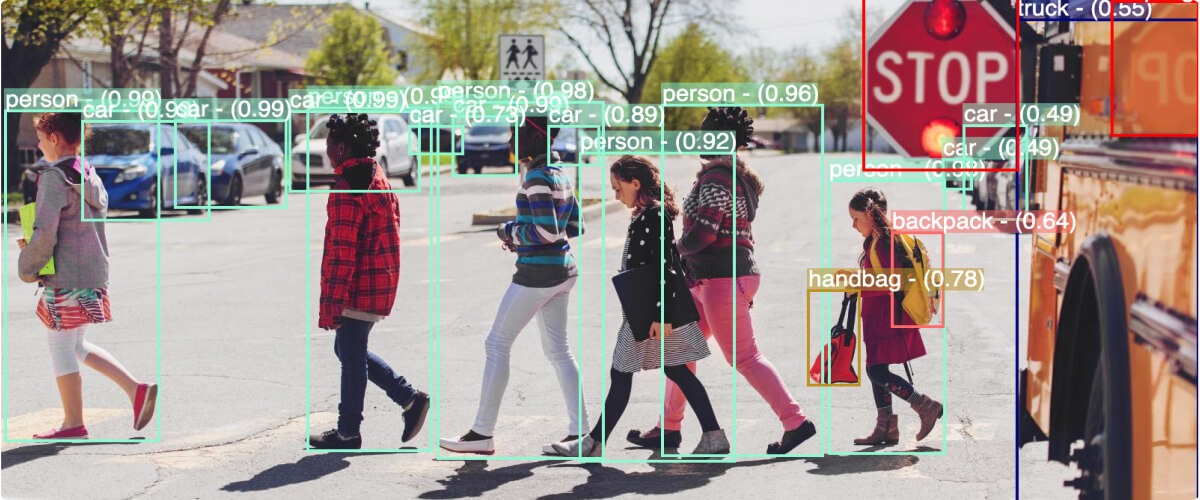
B is for Bounding Boxes: A core technique
In image annotation, bounding boxes are much like the frames we put around our favorite pictures. They provide a way of focusing on specific parts of images. This technique involves drawing a rectangular box around the object we want a machine-learning model to recognize and learn from. Each bounding box comes with a label that denotes what it captures – anything from a “cat” to a “car” or a “person.” Bounding boxes are a staple in object detection tasks, playing a vital role in various applications.
Take, for instance, self-driving cars. These autonomous vehicles are equipped with object detection models that have been trained on images annotated with bounding boxes. These boxes serve as guides, helping the model identify key environmental elements like pedestrians, other vehicles, and road signs. This understanding is crucial for the safe and efficient operation of the vehicle.
However, like any other tool, bounding boxes have strengths and weaknesses. One of its major strengths is simplicity: they are straightforward to understand and implement. This makes them an ideal choice for many object detection tasks. They are also computationally efficient, a valuable attribute in real-time applications where speed is critical.
On the other hand, bounding boxes do have certain limitations. They are less effective when dealing with objects that do not conform to a rectangular shape, as the box may include irrelevant background “noise.” They struggle to differentiate between overlapping objects, as the boxes may encompass more than one object causing ambiguity.
C is for Classes and Categories: Organizing annotations
Organizing annotations into classes and categories plays a vital role in training machine learning models for image annotation tasks. Each labeled item in image annotation belongs to a specific class or category, which can encompass a diverse range of objects or concepts. From concrete objects like “dogs” and “cars” to abstract ideas like “happy” or “dangerous,” the choice of classes depends on the specific computer vision task.
By organizing annotations into classes, we enable the machine learning model to recognize patterns associated with each class. This allows the model to learn and understand the characteristics and features of specific objects distinguishable in one class. As a result, when faced with new, unseen images, the model can accurately predict its appropriate class.
Selecting the right classes is crucial for successfully training machine learning models. The granularity and level of detail in defining classes can significantly impact the model’s performance. Fine-grained classes provide a more specific representation, enabling the model to capture intricate patterns and nuances within the data. Coarse-grained classes offer a more generalized object perspective, which can be advantageous when dealing with large-scale datasets or diverse image collections.
In addition to classes, organizing annotations into meaningful categories further enhances training. Categories provide a hierarchical structure that groups similar classes, facilitating an understanding of relationships and dependencies between annotations. This hierarchical organization helps create a cohesive framework that aids in training models for complex image annotation tasks.
D is for Deep Learning: The power behind computer vision
Deep learning, a subset of machine learning, has emerged as a powerful technology that drives most modern computer vision applications. At the heart of deep learning for computer vision lies Convolutional Neural Networks (CNNs), a specialized neural network designed for image-processing tasks. With their ability to automatically learn and extract features from raw pixel data, CNNs have revolutionized the field of computer vision.
One of the key requirements for deep learning models, including CNNs, is a large amount of annotated data. Annotated data refers to images labeled with precise and accurate annotations, such as bounding boxes, segmentation masks, or keypoint coordinates. These annotations provide ground truth information to the model, allowing it to learn and generalize from the labeled examples.
The quality and thoroughness of the annotations play a crucial role in the deep learning model’s performance. When images are meticulously annotated, capturing detailed information about the objects or concepts of interest, the model gains a more comprehensive understanding of the data. This enables the model to learn intricate patterns and make more accurate predictions when presented with new, unseen images.
E is for Evaluation: Assessing model performance
Once a machine learning model is trained, evaluating its performance is a critical step in understanding its effectiveness and identifying areas for improvement. Evaluation allows us to assess how well the model generalizes new, unseen data and provides insights into its strengths and limitations. One common approach to evaluating model performance in computer vision tasks is using a separate set of annotated images known as the validation set.
The validation set is distinct from the training set and serves as an unbiased sample of data that the model has not yet seen during training. By evaluating the model on this independent set of images, we can obtain a realistic estimation of the model’s performance with unseen data.
During evaluation, the model’s predictions on the validation set are compared to the actual annotations or ground truth labels. This comparison enables the calculation of various evaluation metrics that quantify various aspects of the model’s performance. Some commonly used metrics in computer vision evaluation include precision, recall, and the F1 score.
Evaluation is an iterative process, and it is common to fine-tune models based on the insights gained from the evaluation results. This may involve adjusting model parameters, exploring different training strategies, or collecting additional annotated data to address specific challenges identified during the evaluation.
By continuously evaluating and refining the model’s performance, work can progress in developing robust and reliable computer vision systems. Effective evaluation enables informed decisions, optimized model performance, and ultimately AI systems that meet the highest accuracy, reliability, and usability standards.
F is for Future: AI-assisted image annotation
Looking toward the future, AI-assisted image annotation emerges as a promising development area that can revolutionize the annotation process. By leveraging the power of AI models, we can reduce the workload for human annotators, enhance annotation consistency, and accelerate the overall annotation process.
AI-assisted image annotation involves using machine learning algorithms and computer vision techniques to pre-annotate images automatically. These AI models can be trained on large, annotated datasets, learning to recognize and label objects, regions, or concepts within images. Automating the initial annotation step significantly reduces the burden on human annotators, enabling them to focus on more complex or ambiguous cases that require human expertise.
The advantages of AI-assisted annotation go beyond time savings. With the assistance of AI models, annotation consistency can be greatly improved. Human annotators may introduce inconsistencies or subjective biases in their annotations, but AI algorithms can provide a more objective and standardized approach to labeling images. This ensures more annotation consistency, crucial for training accurate and reliable machine learning models.
Where will the ABCs take you?
Image annotation is a vital process for computer vision, and adhering to the ABCs of image annotation is crucial for accurate and reliable results. At Chooch, we understand the significance of meticulous annotation, whether drawing precise bounding boxes, organizing classes, or evaluating model performance. By adhering to these principles, we ensure annotation quality, consistency, and relevance, enabling the development of robust and effective machine learning models.