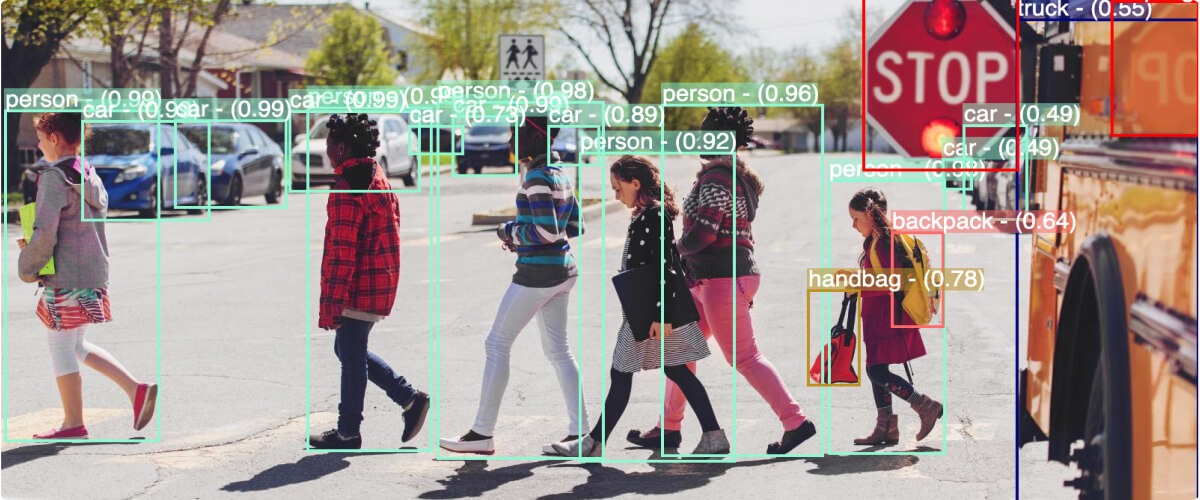
Computer vision is a field of artificial intelligence that enables computers to understand and interpret visual information, just like humans do. By using complex algorithms and techniques, computer vision allows machines to analyze and interpret images or videos — recognizing objects, detecting and tracking movements, and even estimating depth and dimensions.
Computer vision has become an essential technology in various applications such as self-driving cars, surveillance systems, medical imaging, and even social media filters.
What is computer vision?
The origins of computer vision can be traced back to the 1950s when researchers first started exploring ways to mimic human vision using computational techniques.
As technology advanced, so did the capabilities of computer vision systems. The introduction of more powerful hardware, such as GPUs, allowed for faster and more efficient processing of visual data. This, coupled with the development of sophisticated algorithms and machine learning techniques, enabled computer vision systems to tackle more complex tasks.
One of the most significant advancements in recent years has been deep learning. Deep learning is a specialized branch of machine learning that focuses on using artificial neural networks to automatically learn from vast amounts of data and uncover intricate patterns within it. It is critical in computer vision techniques involving pattern recognition, classification, regression, and other complex data analysis tasks.
Let’s take a closer look at how computer vision works and these techniques.
How computer vision works?
Computer vision systems rely on a combination of hardware and algorithms to process visual data. By combining these steps, computer vision algorithms can detect objects, extract relevant features, and make sense of the visual information.
-
- Image acquisition: The process begins with capturing an image or video using cameras or other imaging devices. The quality and resolution of the images acquired influence the accuracy of subsequent computer vision tasks.
- Preprocessing: Once the data is captured, it undergoes preprocessing to clean up the images and adjusts them to make them easier to work with. This might involve removing noise, adjusting colors, and resizing images.
- Feature extraction: Lastly, the computer vision system identifies and extracts important parts of the images, for example color, texture, shape, edges, corners, or any other characteristic that helps the computer understand what is in the images.
Let’s break down a few common scenarios that happen after feature extraction.
The next steps typically involve using those extracted features to perform specific tasks, such as object recognition, classification, segmentation, or any other analysis you might be interested in.

Types of computer vision techniques
Action recognition: Identifies when a person is performing a given action (e.g., running, sleeping, falling, etc.).
Image classification: Categorizes images into predefined classes or categories. The goal is to train a model to recognize and assign a label to an input image based on the features and patterns present in the image.
Image recognition: Identifies the most important high-level contents of an image. For example, given an image of a soccer game, a computer vision model trained for image recognition might return simply “soccer game.”
Image segmentation: Isolates the areas of interest, for example it can separate the foreground (objects of interest) from the background and assigns a category to each pixel in the image, grouping them together into objects, people, backgrounds, etc.
Object tracking: Estimates the motion of objects between consecutive frames.
Machine learning and neural networks: Extracted features often serve as input for machine learning models or deep neural networks. These models learn from the features to make predictions or decisions based on the data they’ve been trained on.
Business impact of computer vision and challenges
Computer vision technology is driving innovation across many industries and use cases and is creating unprecedented business applications and opportunities. It’s being used across all industries to address a broad and growing range of business applications. These include physical security, retail, automotive, robotics, healthcare, manufacturing, supply chain/logistics, government, media and entertainment, and Internet of Things (IoT).
2 major computer vision concerns
As tools and services continue to drive down costs and improve performance and confidence in computer vision systems, there continues to be concerns around ethics and the lack of explainability of sophisticated approaches.
Concerns surrounding privacy and data security continue to be paramount.
Privacy
The ability to capture, analyze, and store substantial amounts of visual data raises questions about who has access to this information and how it is used. Striking the right balance between the benefits of computer vision and protecting individual privacy is a critical consideration in moving forward.
Bias
Computer vision algorithms learn from data, and if the training data is biased, it can lead to biased outcomes. For example, facial recognition algorithms trained on predominantly male faces may struggle to correctly identify female faces. Addressing bias in computer vision algorithms is essential to avoid perpetuating existing societal biases and ensuring fair and ethical use of computer vision technology.
What does the future hold for computer vision
With the continuous advancements in technology and the increasing availability of large datasets, the future of computer vision looks promising. As computer vision systems become more sophisticated and capable, they have the potential to revolutionize various industries and reshape the way we interact with machines.
Gartner predicts based on current trends and projections; computer vision will grow as a popular application for edge deployments – Edge Computer Vision.
“By 2025, Gartner expects computer vision implementations leveraging edge architectures to increase to 60%, up from 20% in 2022.”
Emerging Technologies: Computer Vision Is Advancing to Be Smarter, More Actionable and on the Edge, Gartner July 2022
How can Chooch help computer vision?
Chooch has radically improved computer vision platform with Large Language Models to deliver GenAI-infused computer vision. Chooch combines the power of computer vision with language understanding to deliver more innovative solutions for analyzing video and text data at scale.
Chooch’s Vision AI solutions can process and understand information from multiple types of data sources, such as videos, images, text, and deliver more granular details by recognizing subtle nuances that may not be visible to humans.
Chooch’s computer vision detects patterns, objects, and actions in video images, gathering insights in seconds and can send real-time alerts to people or business intelligence systems to initiate further action in a fraction of the time a human would even notice there might be an issue.
Businesses are using Chooch’s computer vision solutions to build innovative solutions to drive process improvements and improve operations such as retail analytics, manufacturing quality assurance, workplace safety, loss prevention, infrastructure management, and more.
Whether in the cloud, on premise, or at the edge, Chooch is helping businesses deploy computer vision faster to improve investment time to value.
If you are interested in learning how Chooch Vision AI can help you, sign up for a free account or request a demo. For more AI resources check out here.