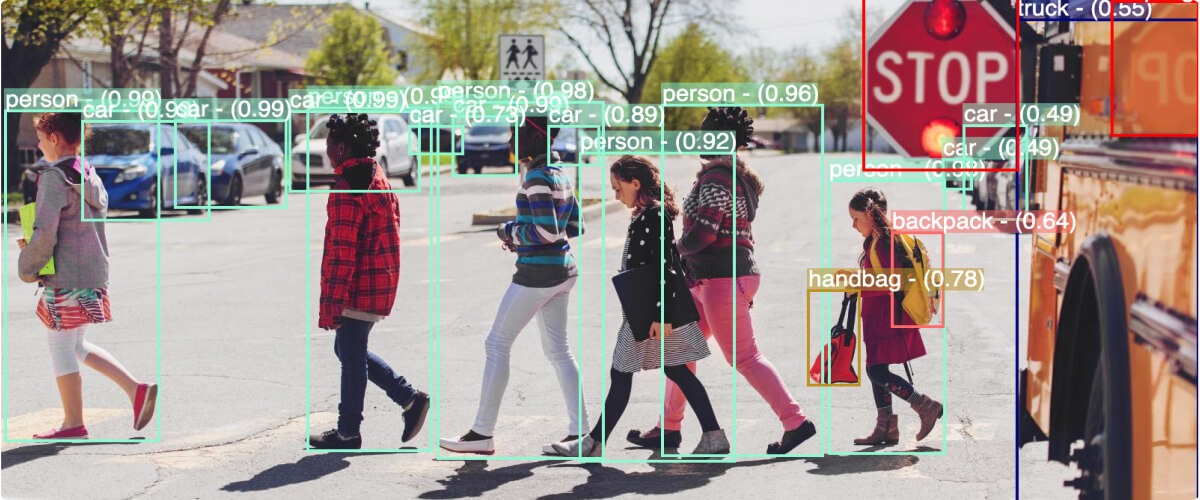
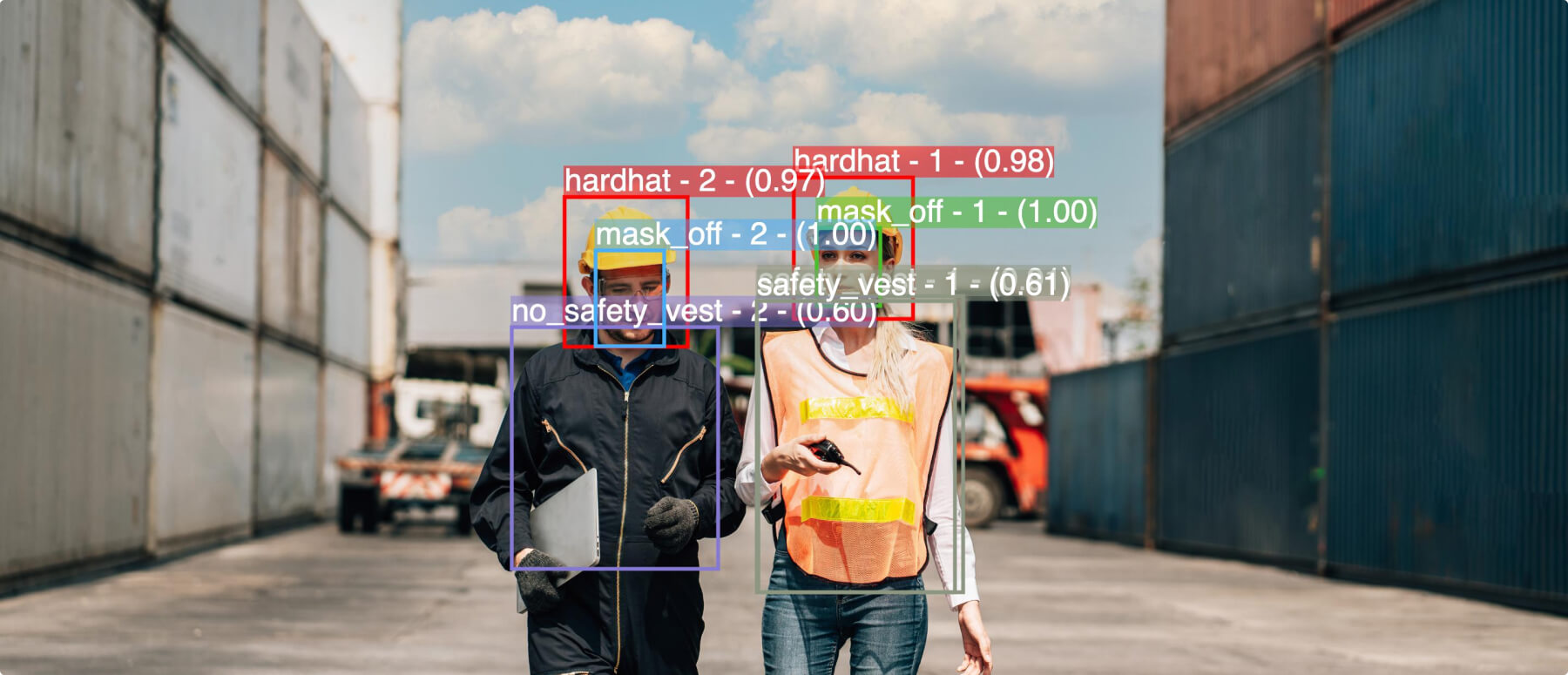
Powered by artificial intelligence and machine learning, computer vision can help digitally transform your business. Today, sophisticated computer vision AI models can learn to recognize a wide variety of faces, objects, concepts, and actions, just as well as—if not even better than—humans can. But…
There’s just one problem: where are you going to get the data? For best results during AI training, you need to collect potentially hundreds or thousands of images or videos. The more training data you can obtain, the better your computer vision models can learn how to classify different visual phenomena.
For example, suppose that you want to build a computer vision model that can differentiate between images of dogs and cats. If you only use high-quality photographs as your training data, with each animal close up and facing the camera, then your model might struggle to generalize to real-world situations, with types of data that it hasn’t seen before. Some difficulties with image recognition are:
- Different viewpoints: The subject may be photographed from many viewpoints, e.g. from behind, from below, from far away, etc.
- Different lighting conditions: The color and appearance of an object (e.g. an animal’s fur) may vary significantly, depending on the amount of light in the photograph.
- Variations within classes: Objects that are classified in the same category may still appear dissimilar—e.g. animals with wildly different colors, breeds, and appearances that are all classified as “dog” or “cat.”
- Occlusion: Computer vision models need to recognize objects that are partially hidden within the image. For example, the model can’t simply learn that all dogs appear to have four legs—or else it won’t recognize dogs inside blankets and dogs looking out a car window.
In order to be responsive to these issues, your computer vision model needs to be trained on large amounts of labeled, high-quality, and highly diverse data. Unfortunately, generating this type of data manually can be difficult and time-consuming.
Solving the Problem of Limited Data for Computer Vision

One solution is to perform data augmentation: increasing the amount of training data by making slight modifications to each image. For example, an image of a dog may be slightly rotated, flipped, shifted, or cropped (or all of the above). This will help the model learn the underlying truth about what a dog looks like, rather than over-fitting by learning to recognize the image itself and knowing that “dog” is the right answer. A single image can produce a dozen or more augmented images that can help your computer vision model extrapolate better in real-world scenarios.
Generating Synthetic Data for Computer Vision
In addition to simple data augmentations, there’s another solution to the problem of data sparsity: you can generate synthetic data.
If you have a realistic 3D model of the object you want to recognize, you can instantly generate hundreds or thousands of images of that 3D object with synthetic data generation.
- You can vary nearly everything about the object and image—viewpoints, pose, backgrounds, lighting conditions, etc.—so that your computer vision model gets a vastly greater range of realistic training data.
- You can automatically create bounding box annotations around the object’s position, rather than having to label each image yourself in a slow, manual process.
- If your 3D model is made up of many smaller parts (e.g. a lawnmower or other machinery), you can even generate data for object segmentation, so that the computer vision model learns to recognize each individual object part.
By using synthetic data generation, computer vision users can rapidly build and iterate AI models and deploy them to the edge.
Chooch is a computer vision vendor that helps businesses of all sizes and industries—from healthcare and construction to retail and geospatial—build cutting-edge computer vision models. Our synthetic data generation feature makes it easy for users to increase the diversity and versatility of their training data. All you need are two files: an .OBJ file that describes the object’s 3D geometry, and an .MTL file that describes the object’s appearance and textures.