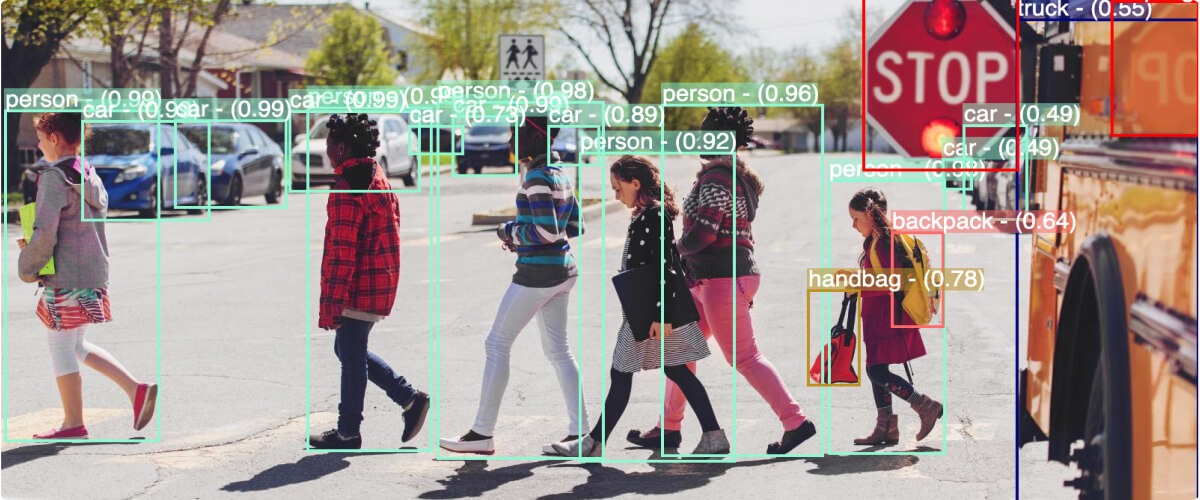
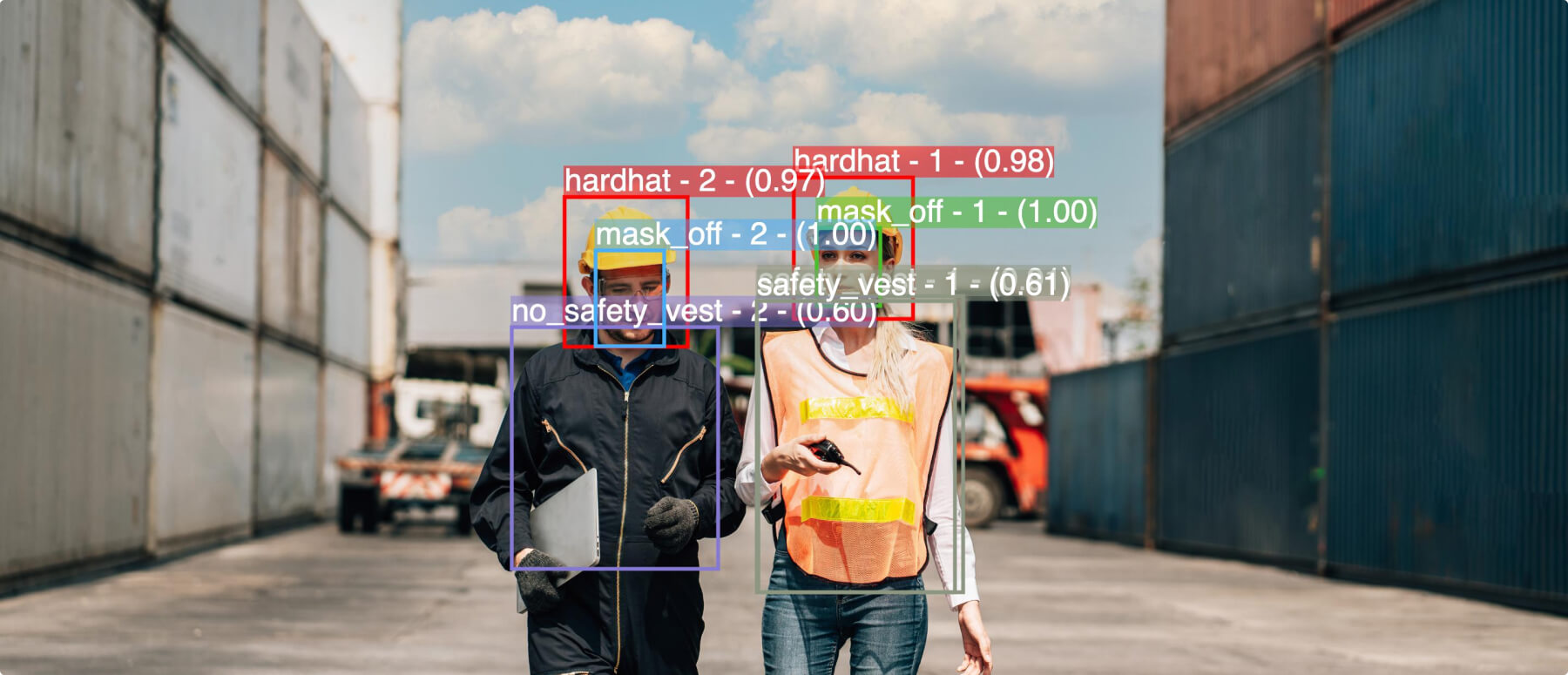
Computer vision and artificial intelligence need a lot of data. The more volume and variety of data that you can show to your model during AI training, the more high-performance and robust the model will be when examining data in the real world that it hasn’t seen before. There’s just one issue: what if you only have a limited amount of data in the first place? That’s where data augmentation comes in.
For example, suppose you want to train a computer vision model to recognize different cat breeds. To achieve the best results, your model should train on a balanced dataset that has roughly the same number of images for each breed. It should be easy enough to find thousands of images of the most popular breeds, such as Persians and Siamese cats, but what about extremely rare breeds such as the LaPerm or the Sokoke?
Without correcting this imbalance, your model can achieve a very high accuracy on the training data simply by learning to recognize the most popular (and therefore overrepresented) breeds. However, this strategy won’t do as well in the real world—for example, a breed recognition quiz that treats all breeds equally, with a single question about each one.
Don’t have enough data to train your AI model? No problem. Below, we’ll discuss a powerful strategy for computer vision to accomplish the (seemingly) impossible: augmenting 2D images.
Data Augmentation for 2D Images

Data augmentation is a useful technique for expanding the size of your dataset without having to find or generate new images. How is this possible? Suppose you have a single image of a cat that you want to augment within your dataset. The transformations that you can make to this image without changing the correct answer (e.g., “Persian” or “American Shorthair”) include:
- Flipping the image (horizontally or vertically)
- Rotating the image
- Scaling the image (e.g., zooming in or out)
- Cropping the image
- Placing the foreground object onto a new background
- Altering the hue of the image
What are the benefits of augmenting 2D images for computer vision? By slightly modifying the original image, you can create perhaps dozens of augmented images. This makes it harder for the AI model to overfit (i.e., learning to recognize the data itself instead of learning the underlying patterns and concepts). For example, a robust AI model for cat breeds should still be able to identify the correct breeds even when the original images are rotated to be upside down.
How to Augment 2D Images with Chooch
There’s just one question left: how can you perform 2D data augmentation for computer vision? Without technical experts on hand, trying to build your own scripts and workflows might suck up valuable time that you could instead spend fine-tuning the model and getting better results.
Fortunately, there’s an answer to this question: powerful, user-friendly computer vision platforms like Chooch. With Chooch, you can augment your existing images in just a few clicks, performing various transformations to make your dataset more robust.
Working in Chooch’s user-friendly dashboard, you can upload an annotated image of your choice, and then select the pre-built transformations and augmentations you want to perform. You can then deploy this model wherever you need it, including on edge devices.
In order to generate the most useful augmented images, data augmentation in Chooch can only be performed on source images with bounding box annotations. The transformations available within the Chooch dashboard for data augmentation include:
- Shifting, scaling, and rotating
- Horizontally flipping
- Cutting out the background
- Adding noise and blurring
- Changing the brightness and contrast
You can choose the default values for these transformations, or tweak and fine-tune the intensity of each augmentation yourself. You can also adjust the number of augmented images to be generated from each source image. Once you’ve adjusted the settings to your liking, Chooch will create the augmented dataset with just a click in a matter of seconds.
Want to learn more about how Chooch can help augment your datasets and improve your AI models’ performance, please visit the Synthetic Data page or request computer vision consulting.